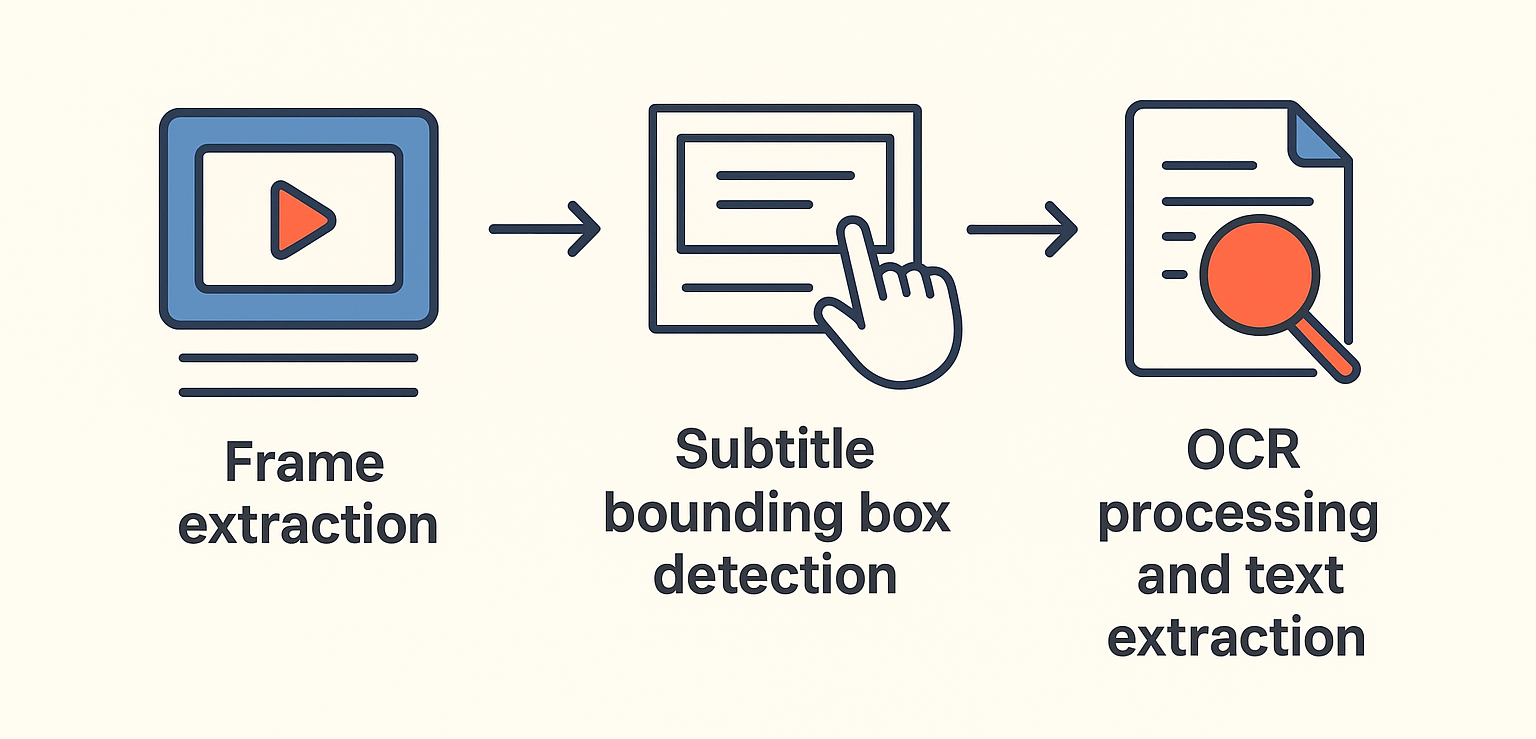
Subtitle extraction from hardcoded video content is a multi-step process that involves a mix of video processing, optical character recognition (OCR), and intelligent data handling. This article aims to provide a clear understanding of each step involved, for anyone who is keen on learning more about this process.
Frame Extraction
The process starts with converting the video into individual frames at a specific frames per second (FPS) rate. The choice of FPS is crucial; a higher FPS captures more frames, which is essential for accurately capturing subtitles, especially when the text changes quickly. However, a higher FPS also means more data to process, which can slow things down. The accuracy of subtitle timestamps depends on the FPS – higher FPS ensures more precise timestamps by reducing the time gap between frames, making it easier to align subtitles with the exact moment they appear and disappear on screen.
Subtitle Bounding Box Detection

Next, we identify the subtitle bounding box. There are a couple of ways to do this. The first is a user-specified bounding box, where users manually draw a box on a frame to indicate where subtitles usually appear. It’s a straightforward method but relies heavily on the user’s accuracy in predicting where subtitles will be. The second method uses computer vision to automate subtitle area detection. This can be done on a per-frame basis, which is more accurate but computationally intensive, or by sampling frames to deduce a general area for subtitles. Sampling is less resource-heavy but might miss out on variations in subtitle placement.
OCR Processing and Text Extraction
The identified area then goes through OCR processing to convert the image-based text into actual text. Current OCR technology is quite adept at handling various font styles and sizes, but it can struggle with highly stylized fonts or low-resolution images. There are different tools for this, like Tesseract and PaddleOCR for open-source solutions, or more powerful, yet paid, cloud-based services like Google Cloud Vision and Amazon, which are often more effective in complex cases.
Post-Processing
In the subtitle extraction process from hardcoded videos, a common issue is the redundancy of subtitles appearing across multiple frames. To address this, text similarity metrics are employed to efficiently merge duplicate subtitles. These metrics, such as Levenshtein distance, which measures the number of edits to transform one string into another, help in evaluating the similarity of extracted text across consecutive frames. High similarity indicates duplicates, allowing for their merger, thus reducing redundant data and streamlining the subtitle file. The cleaned and deduplicated text is then formatted into a SubRip Text (SRT) file. Utilizing the frame numbers, we can infer the correct timestamps for each subtitle, ensuring that they are in sync with the corresponding moments in the video.
Tools and Services for Hardcoded Subtitle Extraction
For those looking to try this themselves, there are various tools available
- video-subtitle-extractor,
- VideoSubFinder (does not perform OCR)
- Videocr
These tools offer flexibility but require some technical know-how and a decent hardware setup. On the other hand, for those preferring a more user-friendly approach, cloud-based services like our own at subtitleextractor.com provide an automated solution that leverages powerful servers and optimized algorithms for quick and accurate results.
Conclusion
In conclusion, extracting subtitles from hardcoded video content involves a balance between precision and efficiency. Whether you opt for a DIY approach with available tools or a cloud-based service, understanding these steps can greatly enhance your ability to perform subtitles extraction from videos.
How to extract Online